Workflow ComfyUI Wan 2.1 : Guide complet et configuration
High-Fidelity Animation Driven by Performer Videos
Wan-Animate can drive any character based on performer videos, accurately replicating facial expressions and body movements. It supports character replacement while matching environmental lighting and color tones, achieving seamless integration of characters in videos.
Abstract
Wan-Animate is a unified framework for character animation generation and replacement. Users only need to provide character images and reference videos to generate high-fidelity animations that precisely replicate the expressions and movements of people in videos. Through environmental lighting and color tone matching, generated characters can seamlessly integrate into original videos, achieving natural replacement.
This framework is based on the Wan model and adopts an improved input paradigm to unify multiple tasks:
- Skeletal Signal Spatial Alignment: Precisely drives body movements
- Implicit Facial Feature Extraction: Highly controllable expression reproduction
- Relighting LoRA Module: Enhances environmental lighting adaptability while maintaining character appearance consistency
Experimental results show that Wan-Animate achieves industry-leading levels in animation quality and environmental integration. Model weights and source code have been open-sourced.
Method
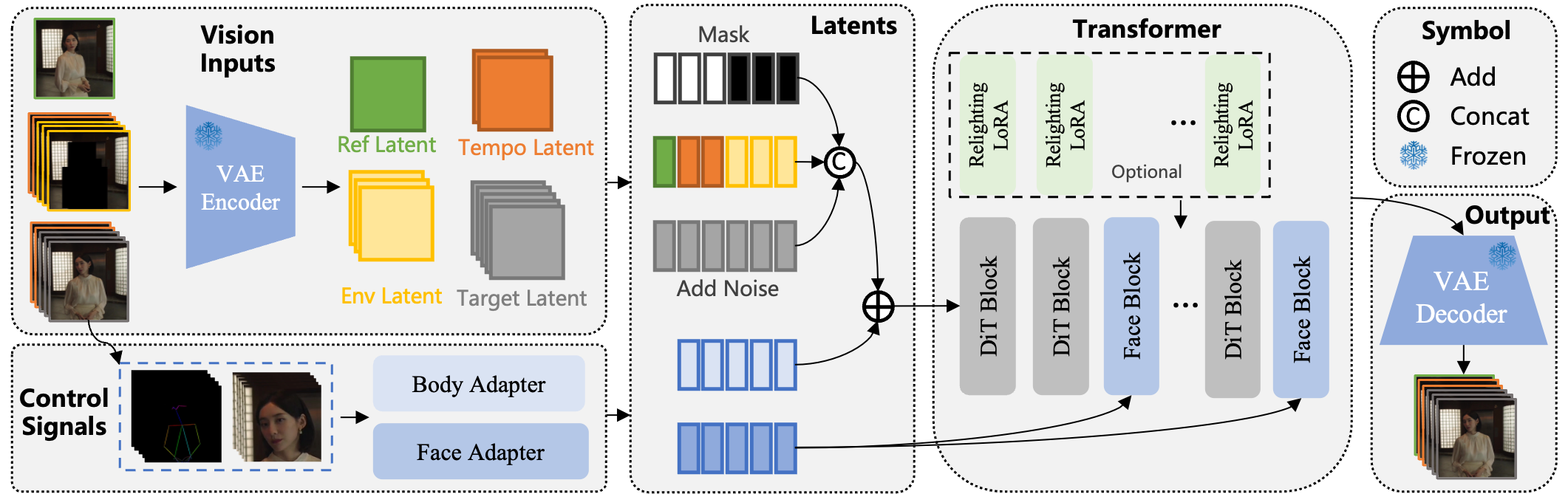
The Wan-Animate architecture is based on Wan-I2V. The input design unifies reference images, temporal frame information, and environmental features into a universal symbolic representation, achieving multi-task compatibility.
- Body Movement Control: Achieves precise control through spatially aligned skeletal signals
- Expression Reproduction: Drives using implicit facial features from source images
- Character Replacement & Environment Adaptation: Auxiliary Relighting LoRA module enhances lighting and color tone integration
This method achieves a unified solution for high-fidelity animation generation and seamless character replacement.